Jan 5, 2022
How my website works
My personal website is an over-engineered playground where I can tinker, learn new things, test new tools, break all the rules, and just scratch that itch deep in my brain that wants to understand how the hell web software works.
My site has gone through several iterations over the years, and what you're seeing now (as of December 2021) is version 5. It's a borderline SaaS-ready web application with all sorts of bells and whistles like user account management, emails, comments, GraphQL, caching, end-to-end tests, and so much more.
While it's somewhat fresh in my head, I wanted to document how this version of the site works, what tools I use to pull it together, and the problems that I had to solve to get everything functioning as you see it today.
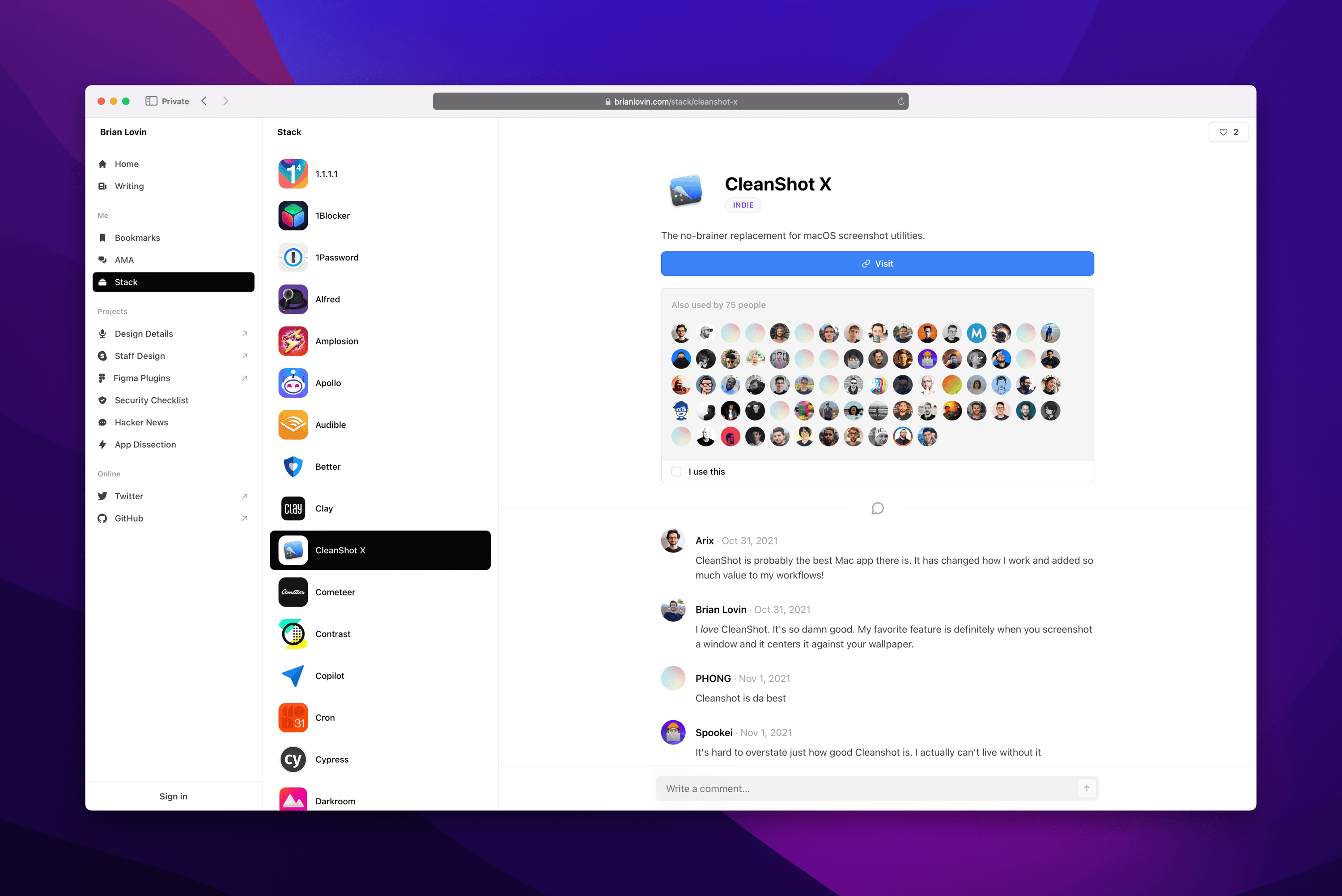
Ideas and goals
Most of the time, I'm just hacking on my site for fun and not-profit. But while building this latest version, I did manage to have a few key ideas and goals in mind:
Reduce friction for iteration and writing
Last year I wrote about why you're not updating your personal website. One of the key reasons I mentioned is that it's too hard to add and edit content for most people who roll their own codebase. If you have to open a pull request every time you want to write a note or make a small edit, you've lost.
So this new version of my website was built with the idea that I should be able to add, edit, and delete content directly from the front-end. This means that everything needs to be backed by a database or CMS, which quickly adds complexity. But at the end of the day, adding a bookmark should be a matter of pasting a URL and clicking save. Writing a blog post should be a matter of typing some markdown and clicking publish.
Extra friction on these processes would make me less likely to keep things up to date or share new things.
A playground for ideas
I've been collecting a list of frameworks and tools to try someday on Github, ranging from front-end JavaScript frameworks to small utilities for writing better CSS. I want my website to be a playground where it's safe to try new technologies and packages in a way that can be easily isolated and easily deleted. This requirement made using Next.js an easy decision because of way it supports hybrid page rendering strategies — static, server-rendered, or client-rendered. More on this below.
Fast
As noted by The Zen of GitHub, "it's not fully shipped until it's fast." While my site isn't the fastest website out there, it's still pretty fast. It turns out it's really hard to make a fast website in 2021, and between caching, preloading, and async computation, I think I've managed to make things feel snappy enough.
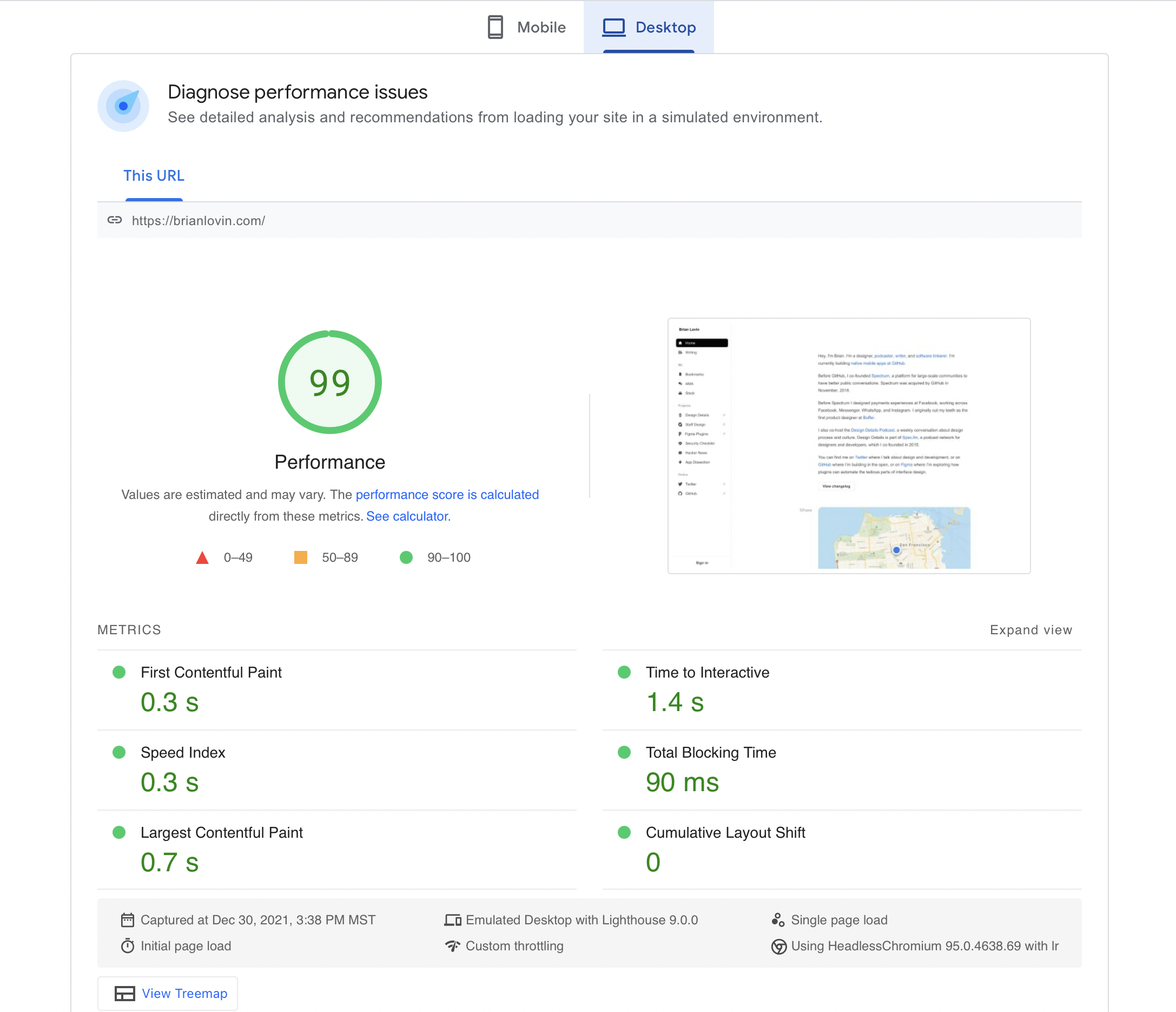
This is particularly important because of the layout I chose: a list-detail multi-column layout affords clicking between lots of different links in a single session, and if those links have just the slightest delay, the whole site can feel sluggish.
Social
One of my goals for this iteration was to make my website feel more social. Specifically, I thought it'd be fun to roll my own comment system so that people could share ideas, leave feedback, or point out any mistakes in my work. In the past, I had an email form at the bottom of each blog post that would send a private email, but making this social and public is more fun and adds real value to future readers.
Front-end
I wanted this version of my site to feel like a web application, mostly because it sounded fun! What would it look like to have a "personal application" that houses all of the things I've made? How would navigation work when I have lots of loosely related projects and content? How could I stretch beyond the single-column personal site design in a way that adds utility and creates creative design and programming problems to learn from?
The result is obviously inspired by macOS and iPadOS, with a global sidebar navigation and a fully responsive multi-column layout. This design makes it easy to jump from anywhere to anywhere, and I love the way the the list-detail layout makes it easier to quickly browse through lots of related content without needing constant back-and-forward navigation.
However, this layout is a pain in the ass to build, for a few reasons:
- Multi-column layouts need to persist many scroll positions as users move between pages.
- Each column needs to maintain its own scroll area, which means having to override the
bodyscrolling behavior. This makes mobile views a huge pain, especially on iOS where you can't rely on having a fixed viewport height. It also breaks helpful shortcuts like tapping on the status bar (on iOS) to quickly jump back to the top of the page. TODO: Figure this out. - My content is a mix of static (e.g. it lives alongside the code, like the Security Checklist page or the App Dissections), third-party (e.g. Hacker News, and first-party (e.g. anything I store in my own database, like my Bookmarks or Stack). Each of these views fetches data in different ways, wants a slightly different layout, and should present a different set of controls. This meant having to think long and hard about component abstractions for things like title bars and action bars.
Next.js
Next.js is my front-end React framework of choice. I particularly enjoy using it because of the file-system based router — it's an intuitive and powerful abstraction for constructing route hierarchy. Next.js also has a huge community of people who have really put the framework through the grinder, sanding down the edge cases and coming up with creative solutions to common problems with React, data fetching, and performance. Whenever I'm stuck, I head to the Next.js Discussions on GitHub and start searching — almost every time there are others before me who have found creative solutions to hard problems.
Next.js is also fast. They do so much optimization for me, either by making my local builds faster, automatically compressing static assets, or making my deployment times blazing fast. The project's regular cadence of updates means my site gets faster over time — for free!
Persisting layouts
One of the absolute hardest problems to solve with this new design was figuring out how to persist each column's scroll position while navigating between pages. For example, if you're viewing the bookmarks list view, and you scroll down, then click an individual bookmark, the list of bookmarks should stay in the same position despite loading an entirely new route and changing the URL.
Another challenge was having the multi-column layout behave correctly on mobile. For example, if someone is viewing the site on a phone, the /bookmarks route should only show a list of bookmarks, and /bookmarks/[id] should only show the bookmark detail. However, on a larger viewport, /bookmarks should show the list of bookmarks with an empty third column placeholder, and /bookmarks/[id] should show both the list of bookmarks and the bookmark detail.
Okay, so how to solve these two problems...
For the scroll persistence, I wish I could take more credit here for figuring out some beautiful abstraction, but I actually picked up most of the hacks from Adam Wathan's blog post, Persistent Layout Patterns in Next.js.
Here's roughly how it works:
- Every page has a static method called
getLayoutthat does some hackery to wrap itself in some global service providers (like the Apollo cache, or Fathom's page view tracking). Let's look at thegetLayoutmethod for rendering a bookmark detail:
BookmarkPage.getLayout = withProviders(function getLayout(page) {
return (
<SiteLayout>
<ListDetailView
list={<BookmarksList />}
hasDetail
detail={page}
/>
</SiteLayout>
)
})Then my global _app.tsx file either executes that getLayout method, or falls back to wrapping the page with providers and the site layout:
export default function App({ Component, pageProps }) {
const getLayout =
Component.getLayout ||
((page) => (
<Providers pageProps={pageProps}>
<SiteLayout>{page}</SiteLayout>
</Providers>
))
return getLayout(<Component {...pageProps} />)
}Okay, the really weird thing about the code above that broke my brain was how we pass the entire page as a component down to the detail view with getLayout(<Component {...pageProps} />).
This means that on the /bookmarks/[id] page, the primary export is just this:
function BookmarkPage({ id }) {
return <BookmarkDetail id={id} />
}Note that this page doesn't render any of the providers, or care about where the component fits into the global multi-column layout — all of that context has been lifted up to the App component. I only care about the detail view itself, the third column, and so that's the only thing this page has to worry about rendering.
Frankly, I don't know exactly how to describe how all of this works without writing a full-on tutorial breaking down the code line by line (which I should probably do anyways, in a separate post!), but I show this code just to point out how weird you have to get with some of the page layout abstractions to "trick" Next.js into persisting a global layout with variable scroll positions across page changes.
As far as the solution for responsive columns: plain ol' CSS! It's all here and here if you want to poke around.
Styling
Tailwind
Tailwind is my favorite CSS-authoring tool...ever? It's really, really good. I wrote about my first impressions last year, and the library has held strong in real-world use. I regularly see threads on Twitter and HN with people arguing about why Tailwind is the best thing ever, or the worst thing ever, and I don't want to wade into that flame war here. I'll say this:
Tailwind is a toolkit that makes everything pretty damn good by default. The magic is in the token system, and the sensible defaults that the team built into the framework. Once I got the hang of Tailwind's semantics, I was really able to start styling my markup at the speed of thought.
Tailwind mostly comes with everything I could need out of the box, but I've slowly added a tiny bit of custom CSS to make things feel a bit more unique. TODO: Inline more of these custom styles using Tailwind's just-in-time mode.
Feel free to poke around here to see what's custom.
Markdown
I've given up on rich text editors on the web. They're so damn complicated, and every tool has their own bespoke abstractions for blocks and elements. We spent hours upon hours trying to solve weird edge cases with rich text while building Spectrum, and I never want to deal with that again.
MDX was a logical tool to reach for next — it cleverly allows for a Markdown-flavored authoring experience, but with the flexibility to embed interactive code, like React components. People like Josh Comeau have made great use of this to build interactive blog posts and engaging tutorials. But again, it just requires so much boilerplate to stand up, and once you start putting React into your Markdown, you're locked in until the next big refactor.
So in the spirit of trying to avoid having to do another huge rewrite in the next couple of years, I looked for the simplest, dumbest solution possible to publishing content on my site: plain text.
The post you're reading now is plain text stored in MySQL, rendered with react-markdown. You can see my custom element renderers here. I can enhance my Markdown using plugins like remark-gfm to add support for tables, strikethroughs, footnotes, and more.
Tradeoffs abound!
Headless UI
The last thing to call out for the front-end is Headless UI, a set of utilities created by the Tailwind crew to provide accessible components like dialogs, menus, switches, and popovers. I'm using it for my dialog component, and found it has the best balance of good-enough defaults with just the right API surface area for customization.
A great alternative to Headless UI is Radix UI.
API
GraphQL
99% of my API operates behind a single /graphql endpoint. I like GraphQL a lot, despite its tradeoffs. The setup is considerably more complicated to stand up, especially in Vercel's world where booting up a GraphQL server can be slow and expensive. And the learning curve for GraphQL is steep: resolvers, schemas, scalars, mutations... But once that hurdle is crossed, the developer experience is wonderful.
All of my GraphQL logic, from queries and mutations, to resolvers and type definitions, is here for the curious.
The hardest thing to figure out with GraphQL was how to make it play nicely with Next.js and to support a mix of SSG, SSR and CSR rendering strategies. My resulting setup is here, based largely on the Next.js example project.
Authentication
Auth0
Auth0 is like a battleship, armed with a million tools and preferences and settings and concepts — all I needed was a sailboat. It's really one of the most overpowered tools in my toolkit, but it was the least-bad way to quickly get user authentication with OAuth set up.
I explored using NextAuth.js instead, but I really didn't like the step where I had to create all my own session tables — maybe I would've been better off, but it's all just trading complexity around at this point.
I integrated Auth0 with the mindset that I should be able to eject from their service at any time in the future when I find a better solution. If a simpler, smaller, hobby-scale authentication provider were to ever come out, I want to be able to swap that in without losing any data. Here's how that works...
Managing user data
When a user logs in, a custom callback handler grabs their public Twitter profile metadata and saves it in my database. Here's how it loosely works:
import { afterCallback } from '~/lib/auth0/afterCallback'
export default handleAuth({
// Custom login and logout handlers here...
async callback(req, res) {
try {
await handleCallback(req, res, { afterCallback })
} catch (error) {
res.status(error.status || 500).end(error.message)
}
},
})import { getUser} from './getUser'
export async function afterCallback(_, __, session) {
const { user } = session
const { sub: id } = user
const details = await getUser(id)
const { description, location, name, nickname, picture, screen_name } =
details
try {
await prisma.user.upsert({
where: {
twitterId: id,
},
update: {
description,
location,
name,
nickname,
avatar: picture.replace('_normal', '_400x400'),
},
create: {
description,
location,
name,
nickname,
avatar: picture.replace('_normal', '_400x400'),
username: screen_name,
twitterId: id,
},
})
} catch (error) {
console.error(error)
}
return session
}If a user's data ever gets stale or out of sync with their Twitter profile, they just need to sign in with Twitter again and this callback handler will save the latest metadata.
From a data retention and privacy perspective, I also built the account system so that when someone wants to delete their account, it will hard-delete all of their data (cascading through any content they created, too) from the database as well as from Auth0's systems. The code lives here.
Database
PlanetScale
With this redesign I wanted to move off of Firebase for many reasons. I find their docs to be confusing, ergonomics unintuitive, and their document-first structure creates a huge hurdle when trying to build anything relational.
PlanetScale is a new "server-less database platform" that runs on MySQL. As a MySQL rookie, PlanetScale provides a beautifully-designed and approachable entry point into the ecosystem and has the best product design among all of the alternatives I evaluated.
Overall, my experience PlanetScale has been incredible. Every once in a while there comes a type of tool that feels like it has perfectly abstracted away all the annoying bits of building software, and left just the right API surface area so that I still feel in control. What I like the most about PlanetScale is one of their keystone features: branching. I can develop on top of a branched version of my database scheme, test different data models and run multiple migrations, and once I'm happy with my solution I can merge that updated schema back to my main branch with zero production downtime. It meshes with how I think about making changes to my codebase, and I can have one mindset no matter where in the stack I'm working.
It's kind of magic, and I know it's only going to get better. I've heard about some of the upcoming features the team is working towards that will make it very, very difficult to "mess up my data" with a bad migration or poorly-written schema.
For fellow designers and side project tinkerers out there who have been intimidated by database software like me, I think PlanetScale is the most approachable solution and has a very generous free tier to play with.
Data fetching
Apollo
Apollo does the heavy lifting to power everything behind the /graphql endpoint. While there are many alternatives, like urql, Apollo is what I'm most familiar with, is relatively mature, and brings a lot of power to the table. For example, native React Hooks support for fetching and mutating data means Apollo feels right at home in my React codebase.
Prisma
Prisma is...incredible? Magic? Both? Specifically, Prisma makes it really easy to interface with a MySQL database, has a deep understanding of my table relationships, and has a lot of under-the-hood performance optimizations like built-in dataloaders to fight the `N+1` problem that is common with GraphQL APIs.
Prism's schema syntax, TypeScript support, and ergonomic API for interfacing with my database has increased my development velocity and helped me learn more about how relational databases work.
If you are interested in learning more about how Prisma, PlanetScale, Next.js, and Vercel can all work together, I highly recommend this tutorial by David Parks: Deploying a PlanetScale, Next.js & Prisma App to Vercel.
GraphCDN
Because my website is such a read-heavy website, caching is one of the biggest levers for making things feel fast and responsive. Unfortunately, it can be really challenging to build a reliable caching system on top of GraphQL, especially when balancing different caching requirements for authenticated users, or the need to have different cache rules on specific fields in a query.
Enter GraphCDN.
With just a bit of setup, I am able to route all of my GraphQL requests through GraphCDN. They can introspect my GraphQL schema and give me controls to customize what kinds of queries and subfields should be cached, and for how long.
As a result, these cached queries are now saving hours of cumulative loading time for visitors to my site, and it's clear there's still a lot more I could be doing to optimize performance:
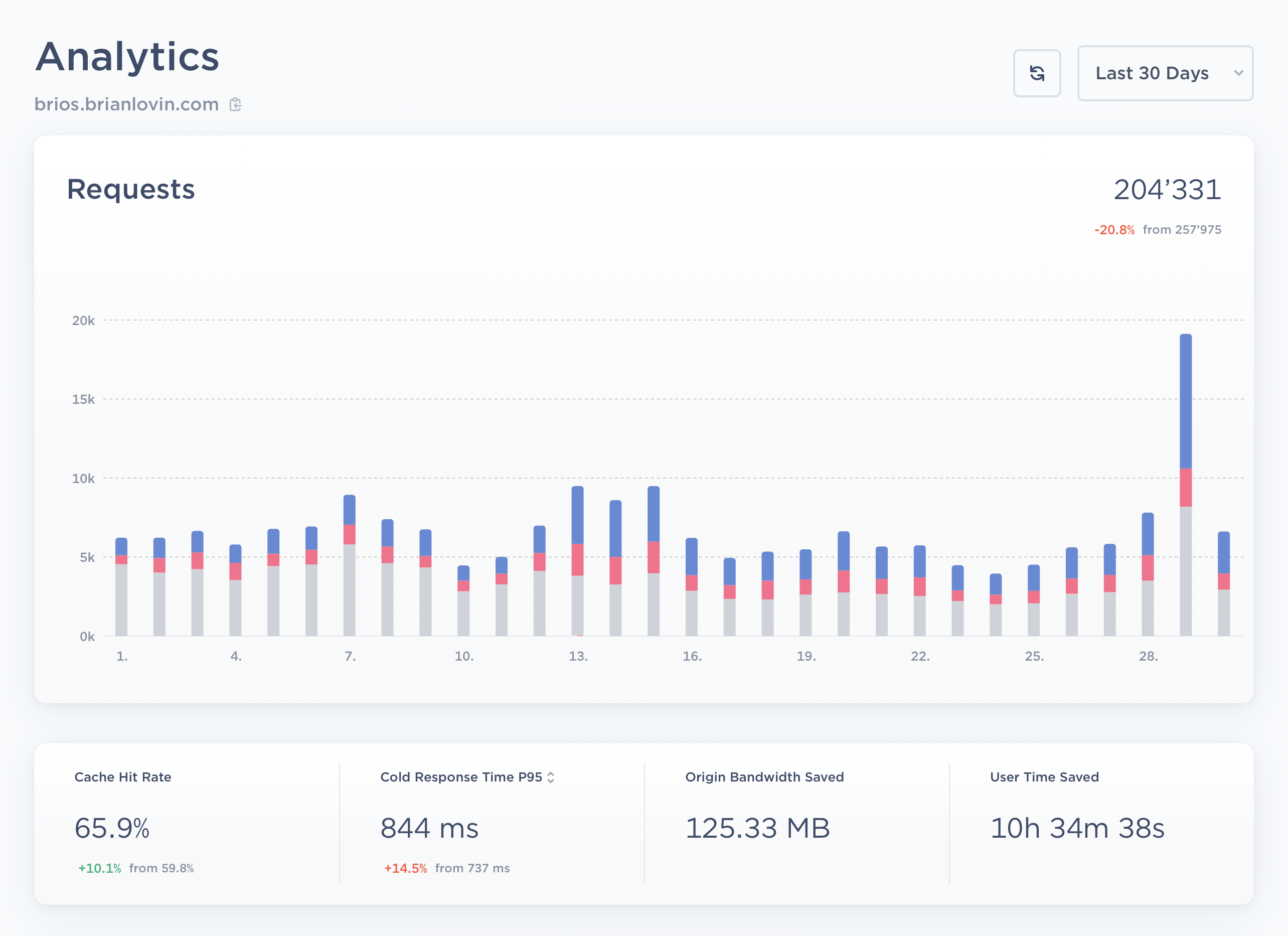
One thing that's really cool about GraphCDN is that they automatically purge the correct objects in the cache whenever I execute a GraphQL mutation, which means I don't have to write as much boilerplate code to invalidate updated records. GraphCDN understands my schema, knows when most objects have been changed, and automatically updates the cache for the next visitor.
Disclaimer: I am an investor in GraphCDN.
Rate limiting
Because I rely on edge functions for data fetching and mutations, someone could take advantage of this and run up my Vercel bill by just brute-forcing requests against my API. To protect against this, I use the Next.js example for API rate-limiting using lru-cache to reject requests above a certain volume per minute.
Bits like this are opportunities for me to learn more about, and practice, defensive coding. In the future, if I work on more important side projects, I'll be happy to know more about protecting against these kinds of edge cases.
Deployment
Vercel
I love Vercel. They deploy my code, host my domains, sync with apps like PlanetScale for seamless integration, and a whole lot more. Because Vercel also maintains Next.js, their integration with my codebase is seamless. Every time I commit code to my repository, Vercel spins up a dedicated preview domain for testing, and I can use that preview to run end-to-end integration tests. Whenever new code is merged into my main branch, Vercel kicks off a production deployment and my changes are live in minutes.
This developer experience becomes magical in combination with services like Dependabot, where I can keep all of my packages up to date and know that every patch is being tested, merged, and deployed to the internet safely in the background.
Services
Postmark
Postmark is a wonderfully effective and simple tool for sending transactional emails. I use it to email myself about new comments on posts, new AMA questions, and send Hacker News Daily Digests.
GraphQL Codegen
GraphQL Codegen watches my project for new or changed GraphQL files, then automatically generates TypeScript type definitions and React Hooks for Apollo. This means that I can write a GraphQL query like this:
import { PostDetailFragment } from '~/graphql/fragments/post'
export const GET_POST = gql`
query getPost($slug: String!) {
post(slug: $slug) {
...PostDetail
}
}
${PostDetailFragment}
`And GraphQL Codegen spits out a handy hook to use in my React components like this:
const { data } = useGetPostQuery({ variables: { slug: propsSlug } })That query will be fully aware of the correct variables to use, what to expect from the data result, and integrates cleanly with Apollo to know about loading states, errors, and more.
Here are my generated hooks and types.
Fathom
Fathom is a privacy-first analytics tool that helps me track page views and traffic to my site over time. It's super lightweight, easy to set up, and I'm a huge fan of Paul and Jack, Fathom's co-founders.
Cloudflare Images
I'm waiting for Cloudflare's upcoming R2 product for storage, but in the meantime I've enjoyed using Cloudflare Images to host my media.
Images is ideal for side projects that have minimal requirements and want the most simple setup possible. For advanced use cases, it's not quite there, but I've been sharing feedback regularly with their team and have seen improvements ship in the past few months.
Vimeo
I use Vimeo Pro to host all of the videos for my App Dissection posts. There are plenty of alternatives to choose from in the video storage and delivery space, but Vimeo hits right right mix customization and control (with direct embeds), while also providing rich analytics.
Testing and automations
GitHub Actions
GitHub Actions run helpful automations when new events happen in my repository. Here are a few that are particularly useful:
- Automerge — tells Dependabot updates to automatically merge package updates as long as all of my tests are passing.
- CodeQL Analysis — uses GitHub CodeQL to detect vulnerabilities in my code.
- GraphCDN — keeps my schema in sync with GraphCDN.
- Hacker News Daily Digest — a cron job that triggers one of my API routes to send a daily digest of the top HN posts.
- Compress images — looks for any images committed to my source files, then compresses and commits the smaller files.
- End-to-end tests — this is the big Action that triggers tests on all new PRs, ensuring that Vercel is able to deploy my code and that I haven't broken core pages on the site.
- Dependabot — keeps my packages up to date, ensuring that bug fixes in my dependencies are patched and merged automatically.
Cypress
Cypress makes it easy to test the end-to-end implementation of my website in a headless browser. This means that before any pull requests are merged, Cypress will generate and preview different pages of my site, check for the existence of certain elements, and fail if anything is broken.
In combination with Dependabot, I can feel confident that my PRs and package updates aren't breaking the core views of the site.
RSS
RSS is an under appreciated, but still important, part of the web ecosystem. To play my part, my blog broadcasts an RSS feed so that anyone can subscribe from the reader of their choice. Right now the feed will only show snippets of blog posts, requiring people to click through to view the full post, but in time I will try to make sure that the RSS feed contains the full body content so that people never have to leave their reader.
The implementation for the RSS feed generation is here.
Metrics
When I shipped this new version of the site, it got some traction on Twitter. I think people were attracted to the multi-column layout that felt like an iPad app, where it's fast to browse lots of different types of content quickly.
One interesting impact of the new design — and a good reminder of why page views are purely a vanity metric — is how my page views to unique visitor ratio spiked.
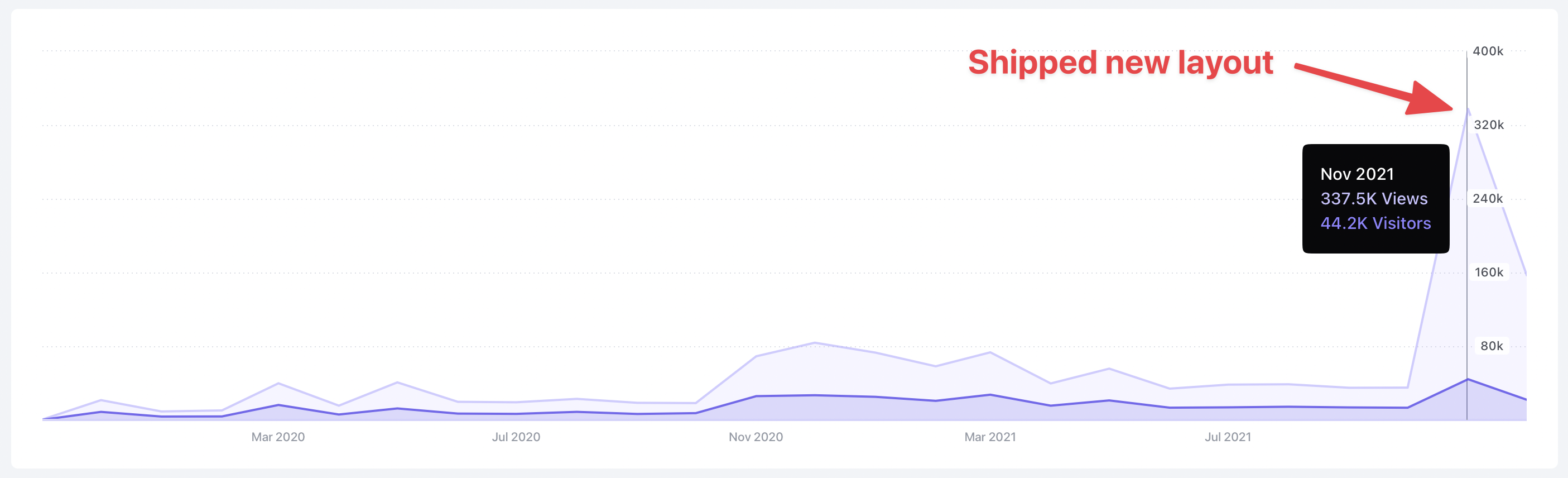
Clearly this is because people used the new layout to navigate in and out of lots of content without necessarily spending a lot of time on any single page. I think the Stack section, in particular, drove a ton of page views because people like discovering new tools and software and were willing to click through several dozen pages in a single visit.
SEO
SEO is a strange craft where it's not always obvious to know what is working and what changes will have the most impact on ranking. But: when it works, it works!
Last year Google sent more than 50,000 people to this site, mostly driven by technical tutorials (which are unfortunately becoming increasingly out of date with each passing month).
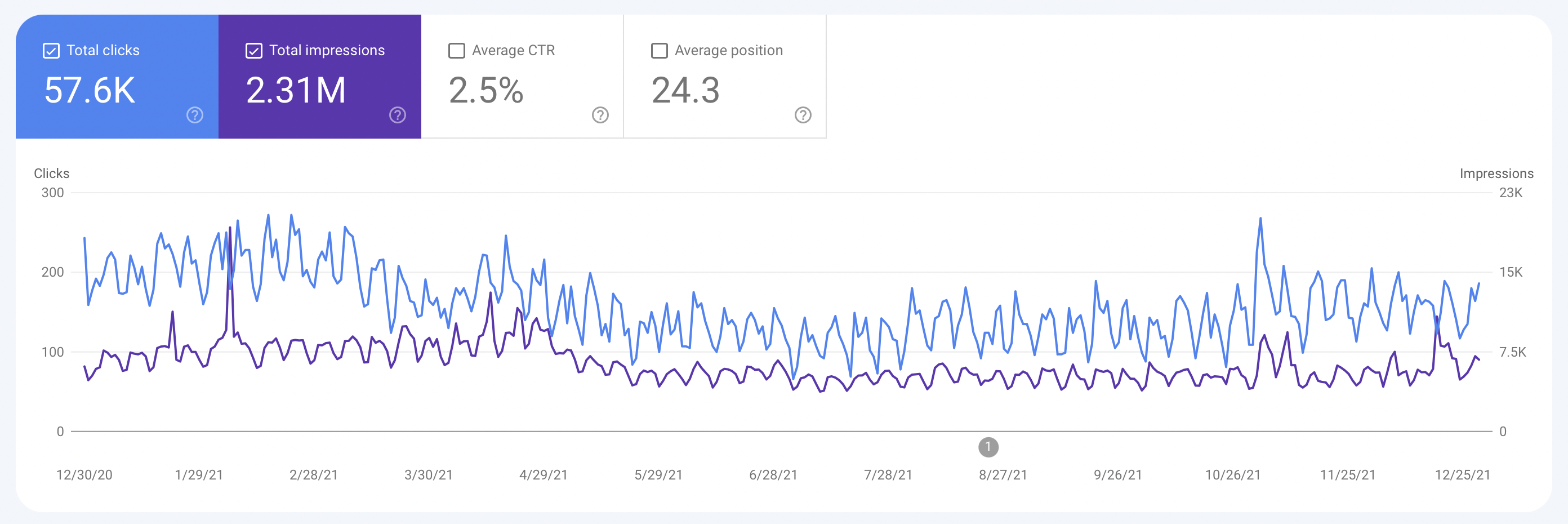
Google searches are the second largest driver of traffic, only behind Twitter. And in a distant third place is GitHub, DuckDuckGo, then Reddit and a handful of other content sites.
My takeaway from tinkering with SEO is that I get the most bang for my buck by writing clear titles, keeping URLs as clear as possible, and making sure my site is fast and optimized for mobile. Everything else feels incremental.
How much everything costs
- Vercel · $20/mo — I'm on the Pro plan and it covers everything I need with room to spare. Some of my edge functions get closer to the plan limits on busy traffic days, which just means I need to invest a bit more time on caching or simplifying my architecture.
- Vimeo · $16/mo — Vimeo gives me direct video embeds with analytics for the App Dissection posts. It might be cheaper to self-host, and considering that I'm not actively uploading new videos this is definitely not the best use of money.
- Domains · $25/mo — almost all of this is because staff.design costs $280/yr. I'm glad to have the domain, but now that it's not an actively maintained side project, I'm not sure what to do.
- Cloudflare Images · $5/mo — this plan lets me store up to 100k images and will cost an additional $1 per 100k images delivered. I don't expect to go over this limit for a long time.
- Fathom · $20/mo — more page views, more problems!
- Google Workspace · $6/mo — this is just to have an email for my domain. Probably not worth it, it's rarely used.
- Other side projects · $40/mo — includes a bunch of other services and domains for my other side projects, like Design Details.
Total: $132/mo or $1.6k/yr
I hadn't put these numbers together in a long time, so I was surprised to see that these services add up to $1.6k/yr. But it's okay because some of my projects make money through sponsorships (Design Details), and I consider this personal site a hobby. As far as hobbies go, it's cheap!
What's next
I've poured hundreds of hours into this website over the last few years. This latest rewrite alone probably took a few dozen hours to build from start to finish. My goal is to use this foundation to add more incremental improvements and features and avoid the trap of doing another big rewrite in the future.
With that in mind, here are a few things I'd like to work on next:
Better end-to-end integration tests
Cypress is great for automatically testing different pages in a browser, but I haven't yet figured out how to write tests that check authenticated views, or tests that perform mutations (like writing comments or signing up). This means that my test suite has a lot of gaps where things could break, and the only way I'd know is if someone were kind enough to reach out.
Notifications
The social features here feel half-baked. Commenting on posts is cool, but nobody gets a heads up when I've replied or someone else has joined the conversation. It would be fun to wire up a lightweight notification system, probably email-first, so that people could know when there are more comments on threads where they've participated, or to be alerted when I've answered their question on the AMA page.
Performance
While I don't think my site is necessarily sluggish today, it could always be faster — I'm sure there's a lot of low-hanging fruit to improve response times from my GraphQL resolvers, and ways to cache data even more aggressively.
Exception tracking
Right now I don't have any observability in place to know if things are breaking. GraphCDN sends me a handful of alerts related to GraphQL, but if something fails on the front-end, or in one of my API routes, I'm oblivious. I'll most likely end up plugging in Sentry, since I've used it many times in the past and am most familiar with their toolset.
Fun things
What else is unlocked with user accounts, comments, and the flexibility of my page layouts? One idea is to have a real-time messaging experience somewhere, maybe in the form of a real-time public interview via chat. Or maybe I could make my blog post drafts public, and people could vote on what ideas are most interesting and share feedback while I'm writing. Or maybe I could make the Home page feel more like a dashboard, giving me quick access to everything important in my digital life. Or maybe it'd be fun to have a mini forum here for product designs to share ideas and talk. Or, what if every page was wired up to Fathom so that all of my analytics were public?
Lots of ideas, not enough time! What sounds fun?
Anything else?
I'd love to hear more from people who might know about better ways to build websites than me. Are any of these tools or technical decisions outdated? What else should I be exploring in the future? If you have thoughts or ideas, please let me know in the comments below!