Get the top HN stories in your inbox every day.
Arcuru
loufe
Is any RL done without unit testing? I would be surprised to hear that that wasn't the case, as it would imply a disregard for accuracy for other model makers, which would be surprising. Perhaps you can do this for small modular problems but not for a problem with a 200k token input?
lvl155
Why are there so many English-first AI models from China? Are they not interested in serving their own population? Or is it that if they publish Chinese-first models it won't get publicity in the West?
throwup238
CommonCrawl [1] is the biggest and most easily accessible legally acquired crawling dataset around, collecting data since 2008. Pretty much everyone uses this as their base dataset for training foundation LLMs and since it's mostly English, all models perform well in English.
whynotmaybe
Haven't we reached a situation where English is the de facto language of scientific research, especially AI benchmarks ?
It's clearly impossible for me to try anything in Chinese, I'd need a translation.
xmichael909
Correct. Lingua franca for at least the last 75 years, if not longer.
numpad0
For publishing results, yes, but not necessarily for the generation part of it.
unsupp0rted
Less and less, it feels like, every year. I wonder if anybody has hard numbers on that.
julianozen
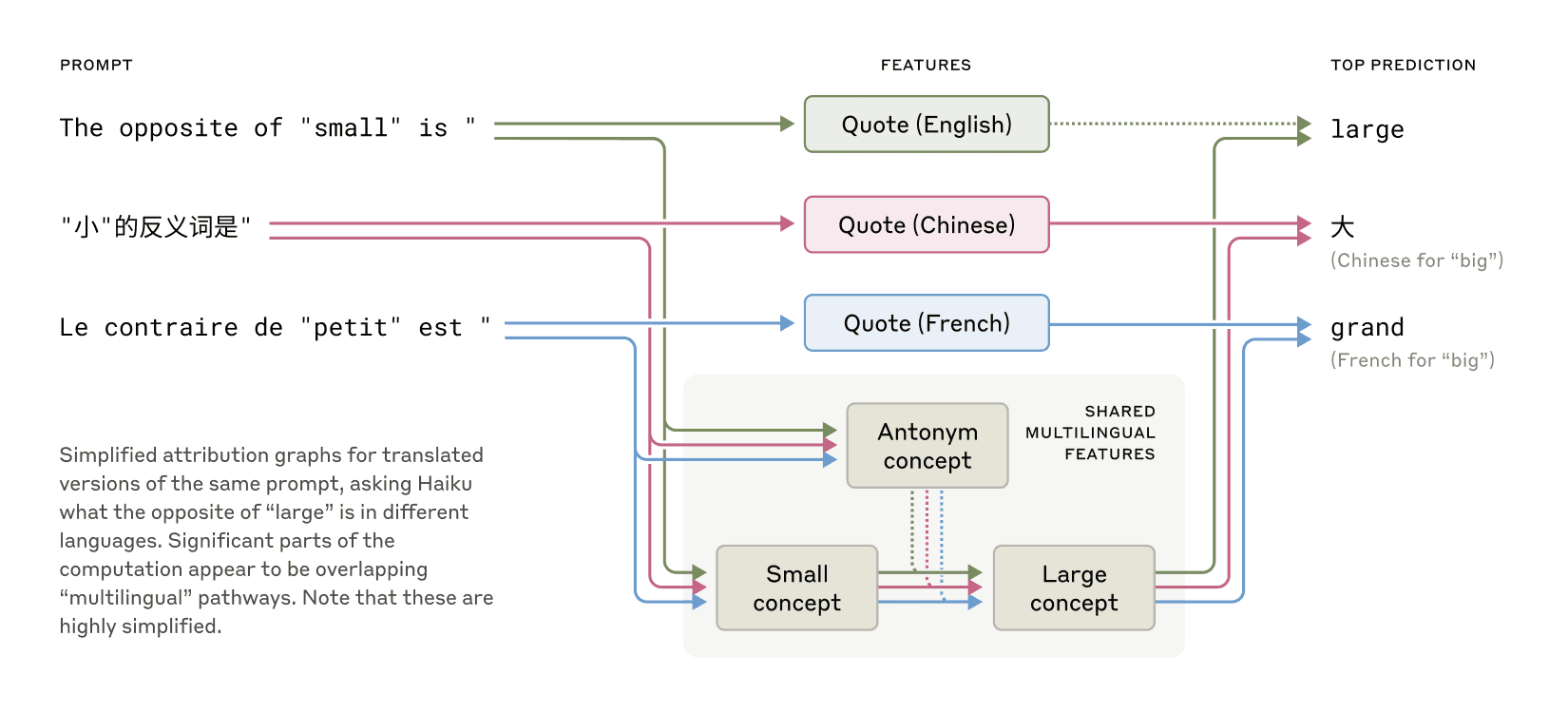
One thing I thought was interesting about this paper [1] on understanding LLMs was how the models associate words/concepts in different languages with each other in what they call Multilingual Circuits.
So the example they give:
English: The opposite of "small" is " → big
French: Le contraire de "petit" est " → grand
Chinese: "小"的反义词是" → 大
Cool graphic for the above [2]
So while English is the lingua franca of the interenet and represents the largest corpus of data, the primary models being built are able to use an English dataset to build associations across languages. This might create significantly stronger AI and reasoning even for languages and regions that lack the data, tech and resources to build local models
[1] https://www.anthropic.com/research/tracing-thoughts-language...
[2] https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-...
{kind=link}
enlyth
I assume a large portion of high quality training material is in English
sigmoid10
You'd be correct. The largest portion of all languages in Common Crawl (aka the "whole open internet" training corpus) is English with 43%. No other language even reaches double digit percentages. The next biggest one is Russian at 6%, followed by German at 5%.
Svoka
I wonder where are you getting your data. According to wikipedia russian is #7 https://en.wikipedia.org/wiki/Languages_used_on_the_Internet
Only place where russian is in top 5 is in Wikipedia views. Russian part of internet steadily goes down, as russian imperialism crumbles.
yyhhsj0521
Chinese internet mostly consists of a few closed gardens tightly controlled by big corps. Crawlers simply don't work when each company employs an army of engineers to guard their data. Many of the most popular websites are also app only. It's impossible to get the corpus necessary to train a good LLM.
AlexCoventry
DeepSeek claims they had 12% more Chinese tokens than English, in their training corpus for DeepSeek V2, FWIW.
https://arxiv.org/pdf/2405.04434#page=12
> Our tokenized pretraining corpus contains 8.1T tokens, where Chinese tokens are approximately 12% more than English ones.
bredren
Do we have estimates on the corpus that is available? This model's repo describes "multiple strategies to generate massive diverse synthetic reasoning data." FWIW, AI 2027 forecasts heavy emphasis on synthetic data creation.
Is the lack of existing corpus just an extra hurdle for Hanzi-first models that are also leading the pack in benchmarks?
chvid
All LLMs are trained on the same basic blob of data - mostly in English, mostly pirated books and stuff.
eru
That's wrong.
Many LLMs are trained on synthetic data produced by other LLMs. (Indirectly, they may be trained on pirated books. Sure. But not directly.)
loufe
Likely the case for established model makers, but barring illegal use of outputs from other companies' models, a "first generation" model would still need this as a basis, no?
Barrin92
>Or is it that if they publish Chinese-first models it won't get publicity in the West?
This is a large part of it. Kai-Fu Lee's company (https://www.01.ai/) has been publishing open source Chinese language/market focused models pretty early, but the entire conversation around Chinese tech just isn't available to you if you don't speak Chinese, in particular these days given that good English language reporting on the Chinese tech sector just seems very scarce.
Leary
They are not "English-first". Deepseek-R1, for example, reasons in Chinese when you ask it a question in Chinese.
eru
I've seen one of the ChatGPT models produce the occasional Chinese phrase even when otherwise reasoning in English about a problem given in English.
HPsquared
Does that apply in other languages too, like French?
siliconc0w
This is incredibly strong coding performance for a 7b. I use Gemini Pro 2.5 which got 67.8 and this got 57.8, very close to Gemini 2.5 Flash which got 60.6.
I've become pretty skeptical about eval results given what we've heard about llama4 so we'll see where this lands on the closed evals but very impressive to see.
jedisct1
GGUF version (for LM Studio, Ollama, etc): https://huggingface.co/jedisct1/MiMo-7B-RL-GGUF
rahimnathwani
When you guys use gguf files in ollama, do you normally create a modelfile to go with it, or just hope that whatever default ollama has work with the new model?
https://github.com/ollama/ollama/blob/main/docs%2Fmodelfile....
Havoc
One of the core design goals Georgi Gerganov had with GGUF was to not need other files. It's literally bullet point #1 in the specs
>Single-file deployment
>Full information: all information needed to load a model is contained in the model file, and no additional information needs to be provided by the user.
https://github.com/ggml-org/ggml/blob/master/docs/gguf.md
We literally just got rid of that multi file chaos only for ollama to add it back :/
rahimnathwani
Most of the parameters you would include in ollama's ModelFile are things you would pass to llama.cpp using command line flags:
https://github.com/ggml-org/llama.cpp/blob/master/examples/m...
If you only ever have one set of configuration parameters per model (same temp, top_p, system prompt...), then I guess you can put them in a gguf file (as the format is extensible).
But what if you want two different sets? You still need to keep them somewhere. That could be a shell script for llama.cpp, or a ModelFile for ollama.
(Assuming you don't want to create a new (massive) gguf file for each permutation of parameters.)
novaRom
This is why we use xdelta3, rdiff, and git
monkmartinez
If you ollama pull <model> the modelfile will be downloaded along with the blob. To modify the model permanently, you can copypasta the modelfile into a text editor and then create a new model from the old modelfile with the changes you require/made.
Here is my workflow when using Open WebUI:
1. ollama show qwen3:30b-a3b-q8_0 --modelfile
2. Paste the contents of the modelfile into -> admin -> models -> OpenwebUI and rename qwen3:30b-a3b-q8_0-monkversion-1
3. Change parameters like num_gpu 90 to change layers... etc.
4. Keep | Delete old file
Pay attention to the modelfile, it will show you something like this: # To build a new Modelfile based on this, replace FROM with: # FROM qwen3:30b-a3b-q8_0 and you need to make sure the paths are correct. I store my models on a large nvme drive that isn't default ollama as an example of why that matters.
EDIT TO ADD: The 'modelfile' workflow is a pain in the booty. It's a dogwater pattern and I hate it. Some of these models are 30 to 60GB and copying the entire thing to change one parameter is just dumb.
However, ollama does a lot of things right and it makes it easy to get up and running. VLLM, SGLang, Mistral.rs and even llama.cpp require a lot more work to setup.
rahimnathwani
Sorry, I should have been clearer.
I meant when you download a gguf file from huggingface, instead of using a model from ollama's library.
monkmartinez
ollama pull hf.co/unsloth/Qwen3-30B-A3B-GGUF:Q4_K_M and the modelfile comes with it. It may have errors in the template or parameters this way. It has to be converted to GGUF/GGML prior to using it this way. You can, of course, convert and create the specific ollama model from bf16 safetensors as well.
o11c
Pretty sure the whole reason Ollama uses raw hashes everywhere is to avoid copying the whole NN gigabytes every time.
monkmartinez
Maybe I am doing something wrong! When I change parameters on the modelfile, the whole thing is copied. You can't just edit the file as far as I know, you have to create another 38GB monster to change num_ctx to a reasonable number.
memhole
I’ll typically use the defaults initially and then use a Modelfile if it’s something I plan on using. I think you can dump the modelfile ollama uses to have a template to work with.
gizmodo59
Its funny to see benchmarks where they omit the top performing models like O3 (Which is the best model in many benchmarks currently) and Gemini Pro/Claude 3.7.
daveguy
Those are much much larger models, and they are proprietary. Those model providers just don't have the distilled versions identified and available.
Notice most of the models they are comparing with are 7B models. The exception is also an open weights model (Qwen-2.5-32B-RL-Zero). Even with 32B parameters the MiMo-7B outperforms it.
erikig
I believe the goal here is to compare them against similar models that are being optimized to run offline or on mobile hardware.
badmonster
MiMo-7B claims to outperform larger models like Qwen-32B and match OpenAI o1-mini on math/code benchmarks — all with a 7B model trained from scratch. Is this a sign that pretraining + RLHF optimization is finally outpacing scale? Or are we just getting better at benchmarking narrow capabilities?
loufe
Qwen 3 or 2.5?
xpe
The README says "RL" without specifying what kind of RL is used. Researchers: I know you are busy, and I know good writing takes time, but please don't skip this kind of detail.
ainch
The technical report does go into a lot of depth about how they use RL, such as the modified GRPO objective they use. As far as the README, I imagine most people active in the field understand the implications of "RL" for a reasoning model.
paulluuk
I assume they mean "Reinforcement Learning", and it's been a decade since I studied AI in university, but isn't it perfectly valid to just say "RL"? What kind of specificity are you looking for, whether they used Q-Learning or some other algorithm?
xpe
I wouldn’t phrase it as a matter of “validity”. I would phrase it as a question of transparency.
Putting a model out in public without clearly explaining how it works doesn’t meet my bar for a proper scientific exchange of knowledge. Perhaps they are being intentionally vague for competitive reasons.
RL is a generic term that can be mixed and matched with various other methods. In the context of LLMs, often some variation of RLHF is used.
But the authors don’t even say “RLHF”, much less explain their methodology. Understanding this isn’t just a matter of academic interest; it has implications for understanding and using this work.
I’m often concerned by the writing quality of ML/AI papers but this strikes me as particularly disappointing.
It is increasingly important to have confidence that the creators of AI systems are thoughtful and thorough. I want to see their reasoning. I want to understand the trade-offs they make and why.
paulluuk
If you put it like that, I absolutely agree with you, except that I suppose I don't really consider this an exchange of knowledge but more like the release of an open-source project: the only thing they need to publish are instructions on how to use it. I don't think they’re really interested in anyone improving their model by themselves or reproducing the work. It would be amazing if they did, though!
Jotalea
I wonder if they will use this model for their AI assistant on their Xiaomi 15 series phones. They most likely will. I'm not really sure what to expect from it.
ramesh31
These benchmark numbers cannot be real for a 7b model
strangescript
The smaller models have been creeping upward. They don't make headlines because they aren't leapfrogging the mainline models from the big companies, but they are all very capable.
I loaded up a random 12B model on ollama the other day and couldn't believe how good it competent it seemed and how fast it was given the machine I was on. A year or so ago, that would have not been the case.
apples_oranges
exactly, it seems to validate my assumption from some time ago, that we will mostly use local models for everyday tasks.
pzo
yeah especially that this simplifies e.g. doing mobile app for 3rd party developers - not extra cost, no need to setup proxy server, monitoring usage to detect abuse, don't need to make complicated subscription plan per usage.
We just need Google or Apple to provide their own equivalent of both: Ollama and OpenRouter so user either use inference for free with local models or BringYourOwnKey and pay themself for tokens/electricity bill. We then just charge smaller fee for renting or buying our cars.
AustinDev
Not just local models but bespoke apps. The number of bespoke apps I've created shot up dramatically in the last 6 months. I use one to do my recipes/meal plan every week. I have one that goes through all my email addresses and summarizes everything daily. I just finished an intelligent planner / scheduler for my irrigation system that takes into account weather forecast and soil moisture levels. If something is annoying and there is no commercial solution or open-source solution that has the features I want I just make it now and it's fantastic.
I've had friends/family ask to use some of them; I declined. I don't want to do support / feature requests.
jillesvangurp
Including figuring out which more expensive models to use when needed instead of doing that by default. Early LLMs were not great at reasoning and not great at using tools. And also not great at reproducing knowledge. Small models are too small to reliably reproduce knowledge but when trained properly they are decent enough for simple reasoning tasks. Like deciding whether to use a smarter/slower/more expensive model.
mring33621
strong agree
my employer talks about spending 10s of millions on AI
but, even at this early stage, my experiments indicate that the smaller, locally-run models are just fine for a lot of tech and business tasks
this approach has definite privacy advantages and likely has cost advantages, vs pay-per-use LLM over API.
wg0
But who will keep them updated and what incentive they would have? That's I can't imagine. Bit vague.
justlikereddit
Last time I did that I was also impressed, for a start.
Problem was that of a top ten book recommendations only the first 3 existed and the rest was a casually blended hallucination delivered in perfect English without skipping a beat.
"You like magic? Try reading the Harlew Porthouse series by JRR Marrow, following the orphan magicians adventures in Hogwesteros"
And the further towards the context limit it goes the deeper this descent into creative derivative madness it goes.
It's entertaining but limited in usefulness.
omnimus
LLMs are not search engines…
nickip
What model? I have been using api's mostly since ollama was too slow for me.
patates
I really like Gemma 3. Some quantized version of the 27B will be good enough for a lot of things. You can also take some abliterated version[0] with zero (like zero zero) guardrails and make it write you a very interesting crime story without having to deal with the infamous "sorry but I'm a friendly and safe model and cannot do that and also think about the children" response.
[0]: https://huggingface.co/mlabonne/gemma-3-12b-it-abliterated
estsauver
Qwen3 and some of the smaller gemma's are pretty good and fast. I have a gist with my benchmark #'s here on my m4 pro max (with a whole ton of ram, but most small models will fit on a well spec'ed dev mac.)
https://gist.github.com/estsauver/a70c929398479f3166f3d69bce...
djmips
Which model?
GaggiX
https://qwenlm.github.io/blog/qwen3/
Go look at the benchmark numbers of qwen3-4B if you think these are unrealistic.
energy123
Also not "real" in the sense that the model developers most likely put the benchmarks into the training data.
bearjaws
My guess is that it is over fitted to the tests.
revel
They used RFT and there's only so many benchmarks out there, so I would be very surprised if they didn't train on the tests.
andrepd
Every LLM is basically being trained on benchmarks so "benchmark" as applied to LLMs is a pretty meaningless term.
mirekrusin
Today's best models will be worse models for the rest of your life.
otabdeveloper4
LLM benchmarks are mostly bullshit right now. Wait a few years until the hype cycle returns to sanity.
xpe
>> These benchmark numbers cannot be real for a 7b model
> LLM benchmarks are mostly bullshit right now. Wait a few years until the hype cycle returns to sanity.
This could mean a lot of things. Can you be a bit more specific? It's one thing to say benchmarks are gamed. Another to say models end up being trained on the benchmark indirectly. Another to say they the particular experimental setup during the benchmark is unclear. Another to say mapping a benchmark to a real use case is hard. Are you saying some/all of these claims?
Have you plotted MiMo versus others? Another comment suggests smaller models are performing better than expected. Any comment on that?
otabdeveloper4
All of these claims and more are true because of perverse incentives right now.
Personally I use Qwen 2.5, works well enough for me. Qwen 3 is a dud.
vessenes
Umm wow. Great benchmarks. I’m looking forward to chatting with this one.
A couple things stand out to me — first is that the 7B model is trained on 25T tokens(!). This is Meta-scale training; Llama 4 Maverick was trained on 22T or so. (Scout, the smaller model: 40T).
Second, this is an interesting path to take - not a distilled model or an RL layer to get reasoning out of another model, but a from-scratch RL model with reasoning baked in; the claims seem to indicate you get a lot of extra efficiency per-parameter doing this.
I don’t have experience with Xiaomi models, so I’m cautious about this one until I play with it, but it looks like a super viable local reasoning model from the stats.
Havoc
Been testing it a bit and overall pretty solid. The lengthy think times means one waits quite a while though. Longer than much larger models like say the recent qwen moe
That moe strikes me as the better overall tradeoff
Get the top HN stories in your inbox every day.
From the paper, I was intrigued by how they handled their RL step for Code Data. They trained against hard but solvable code generation tasks by running unit testing. Is that training step done by the other models?
> Code Data For coding problems, we curate a high-quality training set comprising open-source datasets and our newly collected problem set. We remove problems without test cases. For problems with golden solutions, we exclude those where the golden solution failed to pass all test cases. For problems without golden solution, we discard problems where no test case can be solved in 16 rollouts of advanced reasoning models. Similar to math data, we utilize an SFT version of MiMo-7B to filter out easy problems that are perfectly solved in all 16 rollouts. This rigorous cleaning process yields 30K code problems.
> During each RL iteration, we evaluate thousands of problems to compute the rewards, with each problem potentially containing hundreds of test cases. To improve reward computing efficiency and eliminate GPU idle time, we developed an online judge environment that enables parallel execution of extremely high-volume unit tests.