Get the top HN stories in your inbox every day.
warkanlock
taliesinb
Wow, I love the interactive wizzing around and the animation, very neat! Way more explanations should work like this.
I've recently finished an unorthodox kind of visualization / explanation of transformers. It's sadly not interactive, but it does have some maybe unique strengths.
First, it gives array axis semantic names, represented in the diagrams as colors (which this post also uses). So sequence axis is red, key feature dimension is green, multihead axis is orange, etc. This helps you show quite complicated array circuits and get an immediate feeling for what is going on and how different arrays are being combined with each-other. Here's a pic of the the full multihead self-attention step for example:
https://math.tali.link/raster/052n01bav6yvz_1smxhkus2qrik_07...
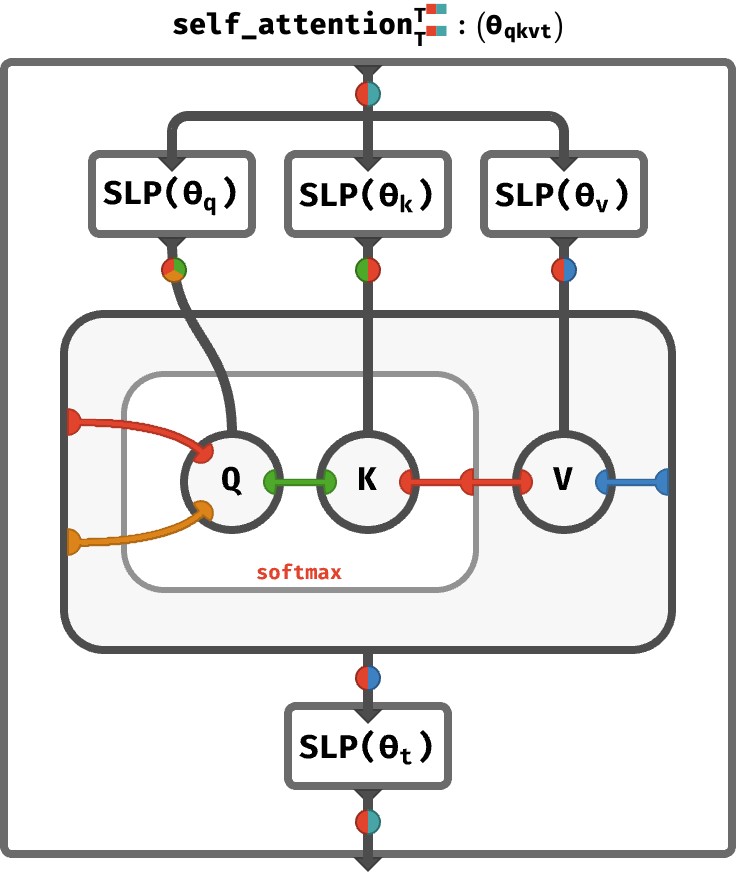{kind=link}
It also uses a kind of generalization tensor network diagrammatic notation -- if anyone remembers Penrose's tensor notation, it's like that but enriched with colors and some other ideas. Underneath these diagrams are string diagrams in a particular category, though you don't need to know (nor do I even explain that!).
Here's the main blog post introducing the formalism: https://math.tali.link/rainbow-array-algebra
Here's the section on perceptrons: https://math.tali.link/rainbow-array-algebra/#neural-network...
Here's the section on transformers: https://math.tali.link/rainbow-array-algebra/#transformers
jimmySixDOF
You might also like this interactive 3D walk through explainer from PyTorch :
riemannzeta
Are you referring specifically to line 141, which sets the number of embedding elements for gpt-nano to 48? That also seems to correspond to the Channel size C referenced in the explanation text?
https://github.com/karpathy/minGPT/blob/master/mingpt/model....
tomnipotent
That matches the name of default model selected in the right pane, "nano-gpt". I missed the "bigger picture" at first before I noticed the other models in the right pane header.
namocat
Yes, thank you - It was unexplained, so I got stuck on "Why 48?", thinking I'd missing something right out of the gate.
zombiwoof
I was thinking 42 ;-)
jayveeone
Yes yes it was the 48 elements thing that got me stuck. Definitely not everything from the second the page loaded.
holtkam2
The visualization I've been looking for for months. I would have happily paid serious money for this... the fact that it's free is such a gift and I don't take it for granted.
terminous
Same... this is like a textbook, but worth it
wills_forward
My jaw drop to see algorhythmic complexity laid out so clearly in a 3d space like that. I wish I was smart enough to know if it's accurate or not.
block_dagger
To know, you must perform intellectual work, not merely be smart. I bet you are smart enough.
nocoder
What a nice comment!! This has been a big failing of my mental model. I always believed if I was smart enough I should understand things without effort. Still trying to unlearn this....
blackbear_
That is a surprisingly common fallacy actually; I think you will find this book quite helpful to overcome it: https://www.penguinrandomhouse.com/books/44330/mindset-by-ca...
modriano
Unfortunately you must look closely at the details to deeply understand how something works. Even when I already have a decent mental heuristic about how an algorithm works, I get a much richer understanding by calculating the output of an algorithm by hand.
At least for me, I don't really understand something until I can see all of the moving parts and figure out how they work together. Until then, I just see a black box that does surprising things when poked.
jampekka
It's also important to learn how to "teach yourself".
Understanding transformers will be really hard if you don't understand basic fully connected feedforward networks (multilayer perceptrons). And learning those is a bit challenging if you don't understand a single unit perceptron.
Transformers have the additional challenge of having a bit weird terminology. Keys, queries and values kinda make sense from a traditional information retrieval literature but they're more a metaphor in the attention system. "Attention" and other mentalistic/antrophomorphic terminology can also easily mislead intuitions.
Getting a good "learning path" is usually a teacher's main task, but you can learn to figure those by yourself by trying to find some part of the thing you can get a grasp of.
Most complicated seeming things (especially in tech) aren't really that complicated "to get". You just have to know a lot of stuff that the thing builds on.
SubiculumCode
99% persperation, 1% inspiration, as the addage goes...and I completely agree.
The frustration for the curious is that there is more than you can ever learn. You encounter something new and exciting, but then you realize that to really get to the spot where you can contribute will take at least a year or six, and that will require dropping other priorities.
gryfft
Damn, this looks phenomenal. I've been wanting to do a deep dive like this for a while-- the 3D model is a spectacular pedagogic device.
quickthrower2
Andrej Karpathy twisting his hands as he explains it is also a great device. Not being sarcastic, when he explains it I understand it for a good minute it two. Then need to rewatch as I forget (but that is just me)!
hodanli
which video specifically?
baq
Could as well be titled 'dissecting magic into matmuls and dot products for dummies'. Great stuff. Went away even more amazed that LLMs work as well as they do.
mark_l_watson
I am looking at Brenden’s GitHub repo https://github.com/bbycroft/llm-viz
Really nice stuff.
flockonus
Twitter thread by the author sharing some extra context on this work: https://twitter.com/BrendanBycroft/status/173104295714982714...
itslennysfault
Thanks for sharing. This is a great thread.
Since X now hides replies for non-logged in user here is a nitter link for those without an account (like me) that might want to see the full thread.
https://nitter.net/BrendanBycroft/status/1731042957149827140
3abiton
I wish it could integrate other open source LLMs in the backend, but this is already an amazing viz.
tysam_and
Another visualization I would really love would be a clickable circular set of possible prediction branches, projected onto a Poincare disk (to handle the exponential branching component of it all). Would take forever to calculate except on smaller models, but being able to visualize branch probabilities angularly for the top n values or whatever, and to go forwards and backwards up and down different branches would likely yield some important insights into how they work.
Good visualization precludes good discoveries in many branches of science, I think.
(see my profile for a longer, potentially more silly description ;) )
29athrowaway
I big kudos to the author of this.
Not only has the visualization, but it's interactive, has explanations for each item, has excellent performance and is open source: https://github.com/bbycroft/llm-viz/blob/main/src/llm
Another interesting visualization related thing: https://github.com/shap/shap
8f2ab37a-ed6c
Expecting someone to implement an LLM in Factorio any day now, we're half-way there already with this blueprint.
Exuma
This is really awesome but I at least wish there were a few added sentences around how I'm supposed to intuitively think about the purpose of why it's like that. For example, I see a T x C matrix of 6 x 48... but at this step, before it's fed into the net, what is this supposed to represent?
singularity2001
Also later why 8 and why is "A" expected in the sixth position
atgctg
A lot of transformer explanations fail to mention what makes self attention so powerful.
Unlike traditional neural networks with fixed weights, self-attention layers adaptively weight connections between inputs based on context. This allows transformers to accomplish in a single layer what would take traditional networks multiple layers.
WhitneyLand
In case it’s confusing for anyone to see “weight” as a verb and a noun so close together, there are indeed two different things going on:
1. There are the model weights, aka the parameters. These are what get adjusted during training to do the learning part. They always exist.
2. There are attention weights. These are part of the transformer architecture and they “weight” the context of the input. They are ephemeral. Used and discarded. Don’t always exist.
They are both typically 32-bit floats in case you’re curious but still different concepts.
airstrike
I always thought the verb was "weigh" not "weight", but apparently the latter is also in the dictionary as a verb.
Oh well... it seems like it's more confusing than I thought https://www.merriam-webster.com/wordplay/when-to-use-weigh-a...
bobbylarrybobby
“To weight” is to assign a weight (e.g., to weight variables differently in a model), whereas “to weigh” is to observe and/or record a weight (as a scale does).
owlbite
I think in most deployments, they're not fp32 by the time you're doing inference no them, they've been quantized, possibly down to 4 bits or even fewer.
On the training side I wouldn't be surprised if they were bf16 rather than fp32.
kirill5pol
I think a good way of explaining #2 is “weight” in the sense of a weighted average
kmeisthax
None of this seems obvious just reading the original Attention is all you need paper. Is there a more in-depth explanation of how this adaptive weighting works?
albertzeyer
The audience of this paper are other researchers who already know the concept of attention, which was very well known already in the field. In such research papers, such things are never explained again, as all the researchers already know this or can read other sources, which are cited, but focus on the actual research questions. In this case, the research question was simply: Can we get away by just using attention and not using the LSTM anymore? Before that, everyone was using both together.
I think learning it following it more this historical development can be helpful. E.g. in this case here, learn the concept of attention, specifically cross attention first. And that is this paper: Bahdanau, Cho, Bengio, "Neural Machine Translation by Jointly Learning to Align and Translate", 2014, https://arxiv.org/abs/1409.0473
That paper introduces it. But even that is maybe quite dense, and to really grasp it, it helps to reimplement those things.
It's always dense, because those papers already have space constraints given by the conferences, max 9 pages or so. To get a better detailed overview, you can study the authors code, or other resources. There is a lot now about those topics, whole books, etc.
BOOSTERHIDROGEN
What books cover exclusively about this topic ? Thanks
WhitneyLand
It’s definitely not obvious no matter how smart you are! The common metaphor used is it’s like a conversation.
Imagine you read one comment in some forum, posted in a long conversation thread. It wouldn’t be obvious what’s going on unless you read more of the thread right?
A single paper is like a single comment, in a thread that goes on for years and years.
For example, why don’t papers explain what tokens/vectors/embedding layers are? Well, they did already, except that comment in the thread came 2013 with the word2vec paper!
You might think wth? To keep up with this some one would have to spend a huge part of their time just reading papers. So yeah that’s kind of what researchers do.
The alternative is to try to find where people have distilled down the important information or summarized it. That’s where books/blogs/youtube etc come in.
andai
Is there a way of finding interesting "chains" of such papers, short of scanning the references / "cited by" page?
(For example, Google Scholar lists 98797 citations for Attention is all you need!)
kaimac
I found these notes very useful. They also contain a nice summary of how LLMs/transformers work. It doesn't help that people can't seem to help taking a concept that has been around for decades (kernel smoothing) and giving it a fancy new name (attention).
http://bactra.org/notebooks/nn-attention-and-transformers.ht...
CyberDildonics
It's just as bad a "convolutional neural networks" instead of "images being scaled down"
gtoubassi
I struggled to get an intuition for this, but on another HN thread earlier this year saw the recommendation for Sebastian Raschka's series. Starting with this video: https://www.youtube.com/watch?v=mDZil99CtSU and maybe the next three or four. It was really helpful to get a sense of the original 2014 concept of attention which is easier to understand but less powerful (https://arxiv.org/abs/1409.0473), and then how it gets powerful with the more modern notion of attention. So if you have a reasonable intuition for "regular" ANNs I think this is a great place to start.
andai
Turns out Attention is all you need isn't all you need!
(I'm sorry)
pizza
softmax(QK) gives you a probability matrix of shape [seq, seq]. Think of this like an adjacency matrix with edges with flow weights that are probabilities. Hence semantic routing of parts of X reduced with V.
where
- Q = X @ W_Q [query]
- K = X @ W_K [key]
- V = X @ V [value]
- X [input]
hence
attn_head_i = (softmax(Q@K/normalizing term) @ V)
Each head corresponds to a different concurrent routing system
The transformer just adds normalization and mlp feature learning parts around that.
lchengify
Just to add on, a good way to learn these terms is to look at the history of neural networks rather than looking at transformer architecture in a vacuum
This [1] post from 2021 goes over attention mechanisms as applied to RNN / LSTM networks. It's visual and goes into a bit more detail, and I've personally found RNN / LSTM networks easier to understand intuitively.
[1] https://medium.com/swlh/a-simple-overview-of-rnn-lstm-and-at...
Get the top HN stories in your inbox every day.
This is an excellent tool to realize how an LLM actually works from the ground up!
For those reading it and going through each step, if by chance you get stuck on why 48 elements are in the first array, please refer to the model.py on minGPT [1]
It's an architectural decision that it will be great to mention in the article since people without too much context might lose it
[1] https://github.com/karpathy/minGPT/blob/master/mingpt/model....