Get the top HN stories in your inbox every day.
Waterluvian
netruk44
If it helps you to understand at all, assuming you have a CS background, any time you see the word "tensor" you can replace it with "array" and you'll be 95% of the way to understanding it. Or "matrix" if you have a mathematical background.
Whereas CS arrays tend to be 1 dimensional, and sometimes 2 dimensional, tensors can be as many dimensions as you need. A 256x256 photo with RGB channels would be stored as a [256 x 256 x 3] tensor/array. If you want to store a bunch of them? Add a dimension to store each image. Want rows and columns of images? Make the dimensions [width x height x channels x rows x columns].
minimaxir
A more practical example of the added dimensionality of tensors is the addition of a batch dimension, so a 8 image batch per training step would be a (8, 256, 256, 3) tensor.
Tools such as PyTorch's DataLoader can efficiently collate multiple inputs into a batch.
brundolf
This is something that infuriates me about formal mathematics (and CS, for that matter): they don't just use the words people already know! They have to make up new words, sometimes even entirely new symbols, that often just mean the same thing as something else. And then the literature becomes entirely inaccessible unless you've learned this secret code. The bottleneck becomes translation, instead of understanding.
Breza
I agree with you. Fields like graph theory and set theory are fun once you wrap your head around the symbols, but I remember having a lot of trouble with both as a teenager.
pmoriarty
"Whereas CS arrays tend to be 1 dimensional, and sometimes 2 dimensional, tensors can be as many dimensions as you need."
You can have arrays of as many dimensions as you need in many (most?) programming languages.
Is there some other difference between tensors and arrays?
Or is it just the math term for multidimensional array?
nh23423fefe
Essentially the same difference between vectors and arrays. A vector is an element of a vector space. A vector can be represented as a coordinate array in a basis, but it is not the coord array. Consider the vector 1 + x + x^2 you might use the canonical basis for polynomials {1, x, xx, xxx, ...} and then the coordinate vector is [1 1 1]. The coordinate and the basis represent the polynomial. But the polynomial isn't a list of numbers.
A matrix is the coefficient list of a linear transformation, but it is not the transformation. The derivative operator is a linear transformation. It's representation as a matrix is just coordinates. But the operator is clearly more than that.
A tensor can be written down and you can compute with the components, but the tensor itself is the basis independent transformation. Not a list of components.
netruk44
I didn't mean to imply you couldn't have an n-dimensional array in many programming languages. Just that it's usually not what's done when designing programs. I think many would prefer to make some kind of object to encapsulate the data type (an RGB struct for my example) instead of making arrays of arrays of arrays of (double/float/uint8).
For the literal definition between a mathematical 'tensor' and a (e.g.) PyTorch 'tensor' (which, from reading the other comments here, are not the same thing), I leave that to other commenters. I'm just someone learning PyTorch and sharing my knowledge.
The practical engineering difference between a PyTorch tensor and Python array is that PyTorch comes with tons of math & utility functions that support n-dimensions and are differentiable, whereas the builtin Python arrays and math utilities don't do much, if any, of that.
Waterluvian
This helps. Thank you. Any advice on where to look to understand why the word tensor was used?
pvarangot
A Tensor is a mathematical object for symbolic manipulation of relationships between other objects that belong in conceptually similar universes or spaces. Literature on Deep Learning, like Goodfellow, call for the CS-minded reader to just assume it's a fancy word for a matrix of more than two dimensions. That makes matters confusing because mathematically you could have scalar or vectorial tensors. The classic mathematical definition puts more restrictions on the "shape" of the "matrix" by requiring certain properties so that it can create a symbolic language for a tensor calculus. Then you can study how the relationships change as variables on the universes or spaces change.
Understanding the inertia tensor on classical mechanics or the stress tensor may illustrate where tensors come from, and I understand that GR also makes use of a lot of tensor calculus that came to be as mathematics developed manipulating and talking about tensors. I have a kinda firm grasp on some very rudimentary tensor calculus from trying to leanr GR, and a pretty solid grasp on classical mechanics. I've had hour long conversations with deep learning popes and thought leaders in varying states of mind and after that my understanding is that they use the word tensor in an overreaching fashion as like you could call a solar panel a nuclear fission reactor power source. This thought leaders include people with books and 1M+ view Youtube videos on the subject that use the word tensor and I'm not saying their names because they off-the-record admitted that it's a poor choice of term but it harms the ego of many Google engineers to publicly admit that.
jayalammar
I updated the post to say "multi-dimensional array".
In a context like this, we use tensor because it allows for any number of dimensions (while vector/ array is only one, matrix is two). When you get into ML libraries, both popular packages PyTorch and TensorFlow use the "tensor" terminology.
It's a good point. Hope it's clearer for devs with "array" terminology.
kgwgk
It’s a cool name from the good ol’ “multi-dimensional arrays with a uniform type”
jamessb
Very loosely, a number/vector/matrix/tensor can be considered to be objects where specifying the values of 0/1/2/3 indexes will give a number.
(A mathematician might object to this on several grounds, such as that vectors/matrices/tensors are geometric objects which need not be expressed numerically as coordinates in any coordinate system)
sva_
It should be noted that it doesn't have all to much to do with the rigorous mathematical definition of a Tensor.
undefined
avereveard
To reduce it a little, matrix holds numbers, tensor holds whatever. Numbers. Vectors. Operations.
TigeriusKirk
One of my favorite moments in Geoffrey Hinton's otherwise pretty info-dense Coursera neural network class was when he said-
"To deal with a 14-dimensional space, visualize a 3-D space and say 'fourteen' to yourself very loudly. Everyone does it."
TuringTest
Kudos to this. It also helps to think of a three-dimensional space bounded by the sides of a box, and to think of another 11 boxes stacked on top of each other.
Then, you can visualize orthogonal on dimensions higher than 3 by throwing wires between equivalent points in two boxes.
pmoriarty
"It also helps to think of a three-dimensional space bounded by the sides of a box, and to think of another 11 boxes stacked on top of each other."
Of course the problem with that is that you're still thinking three-dimensionally because "on top of" is a description of a 2D or 3D relationship.
dr_dshiv
Or imagine a spreadsheet with 14 columns, amiright?
beernet
I think this post explains tensors fairly well: https://www.kdnuggets.com/2018/05/wtf-tensor.html
Quote: "A tensor is a container which can house data in N dimensions. Often and erroneously used interchangeably with the matrix (which is specifically a 2-dimensional tensor), tensors are generalizations of matrices to N-dimensional space."
undefined
pdntspa
I got lost at the word 'tensor' too, but then I just googled it and skilled up...
But simply put, a 'tensor' is a 3+-dimensional array of floats. Or a stack of matrices.
Waterluvian
I should have added that the images/figures really help. I think I’m about there.
undefined
6gvONxR4sf7o
You’re talking like using jargon makes something a bad explanation, but maybe you just aren’t the audience? Why not use words like that if it’s a super basic concept to your intended audience?
Waterluvian
I saw the scientific term, “Text Understander” and wrongly thought I was the audience.
ultrasounder
Kudos to Author for writing this. The author's other guide, https://jalammar.github.io/gentle-visual-intro-to-data-analy... is THE most approachable introduction to Pandas for Excel users like me who are "comfortable" with Python(disclaimer: Self taught EE/Hardware guy). I will definitely spend some time this weekend to go over this tome. Thanks again.
minism
Great overview, I think the part for me which is still very unintuitive is the denoising process.
If the diffusion process is removing noise by predicting a final image and comparing it to the current one, why can't we just jump to the final predicted image? Or is the point that because its an iterative process, each noise step results in a different "final image" prediction?
psb217
In the reverse diffusion process, the reason we can't directly jump from a noisy image at step t to a clean image at step 0 is that each possible noisy image at step t may be visited by potentially many real images during the forward diffusion process. Thus, our model which inverts the diffusion process by minimizing least-squares prediction error of a clean image given a noisy image at step t will learn to predict the mean over potentially many real images, which is not a itself a real image.
To generate an image we start with a noise sample and take a step towards the _mean_ of the distribution of real images which would produce that noise sample when running the forward diffusion process. This step moves us towards the _mean_ of some distribution of real images and not towards a particular real image. But, as we take a bunch of small steps and gradually move back through the diffusion process, the effective distribution of real images over which this inverse diffusion prediction averages has lower and lower entropy, until it's effectively a specific real image, at which point we're done.
wokwokwok
> But, as we take a bunch of small steps and gradually move back through the diffusion process...
...but, the question is, why can't we take a big step and be at the end in one step.
Obviously a series of small steps gets you there, but the question was why you need to take small steps.
I feel like this is just a 'intuitive explanation' that doesn't actually do anything other than rephrase the question; "You take a series of small steps to reduce the noise in each step and end up with a picture with no noise".
The real reason is that big steps result in worse results (1); the model was specifically designed to be a series of small steps because when you take big steps, you end up with over fitting, where the model just generates a few outputs from any input.
psb217
The reason why big steps produce worse results, when using current architectures and loss functions, is precisely because the least squares prediction error and simple "predict the mean" approach used to train the inverse model does not permit sufficient representational capacity to capture the almost always multimodal conditional distribution p(clean image | noisy image at step t) that the inverse model attempts to approximate.
Essentially, current approaches rely strongly on an assumption that the conditional we want to estimate in each step of the reverse diffusion process is approximately an isotropic Gaussian distribution. This assumption breaks down as you increase the size of the steps, and models which rely on the assumption also break down.
This is not directly related to overfitting. It is a fundamental aspect of how these models are designed and trained. If the architecture and loss function for training the inverse model were changed it would be possible to make an inverse model that inverts more steps of the forward diffusion process in a single go, but then the inverse model would need to become a full generative model on its own.
a1369209993
> why can't we take a big step and be at the end in one step.
Because we're doing gradient descent. (No, seriously, it's turtles all the way down (or all the way up, considering we're at a higher level of abstraction here).)
We're trying to (quickly, in less than 100 steps) descend a gradient through a complex, irregular and heavily foggy 16384-dimensional landscape of smeared, distorted, and white-noise-covered images that kinda sorta look vaguely like what we want if you squint (well, if the neural network squints, anyway). If we try to take a big step, we don't descend the gradient faster; we fly off in a mostly random direction, clip through various proverbial cliffs, and probably end up somewhere higher up the gradient than we started.
ttul
This is the best explanation I have ever read - on any topic.
minism
Thank you! This is a great explanation.
mota7
The problem is that predicting a pixel requires knowing what the pixels around it looks like. But if we start with lots of noise, then the neighboring pixels are all just noise and have no signal.
You could also think of this as: We start with a terrible signal to noise ratio. So we need to average over very large areas to get any reasonable signal. But as we increase the signal, we can average over a smaller area to get the same signal-to-ratio.
In the beginning, we're averaging over large areas, so all the fine detail is lost. We just get 'might be a dog? maybe??'. What the network is doing is saying "if this a dog, there should be a head somewhere over here. So let me make it more like a head". Which improves the signal to noise ratio a bit.
After a few more steps, the signal is strong enough that we can get sufficient signal from smaller areas, so it starts saying 'head of a dog' in places. So the network will then start doing "Well, if this is a dog's head, there should be some eyes. Maybe two, but probably not three. And they'll be kinda somewhere around here".
Why do it this way?
Doing it this ways means the network doesn't need to learn "Here are all the ways dogs can look". Instead, it can learn a factored representation: A dog has a head and a body. The network only needs to learn a very fuzzy representation at this level. Then a head has some eyes and maybe a nose. Again, it only needs to learn a very fuzzy representation and (very) rough relative locations.
So it only when it get right down into fine detail that it actually needs to learn pixel perfect representation. But this is _way_ easier, because in small areas images have surprisingly very low entropy.
The 'text-to-image' bit is a just a twist on the basic idea. At the start when the network is going "dog? or it might be a horse?", we fiddle with the probabilities a bit so that the network starts out convinced there's a dog in there somewhere. At which point it starts making the most likely places look a little more like a dog.
sroussey
I suppose that static plus a subliminal message would do the same thing to our own numeral networks. Or clouds. I can be convinced I’m seeing almost anything in clouds…
astrange
Research is still ongoing here, but it seems like diffusion models despite being named after the noise addition/removal process don't actually work because of it.
There's a paper (which I can't remember the name of) that shows the process still works with different information removal operators, including one with a circle wipe, and one where it blends the original picture with a cat photo.
Also, this article describes CLIP being trained on text-image pairs, but Google's Imagen uses an off the shelf text model so that part doesn't seem to be needed either.
krackers
I think it might be this paper [1] succintly described by the author in this twitter thread [2]
[1] https://arxiv.org/abs/2208.09392 [2] https://twitter.com/tomgoldsteincs/status/156250381442263040...
dougabug
If you removed all of the noise in a corrupted image in one step, you would have a denoising autoencoder, which has been around since the mid-aughts or perhaps earlier. Denoising diffusion models remove noise a little bit at a time. Think about an image which only has a slight amount of noise added to it. It’s generally easier to train a model to remove a tiny amount of noise than a large amount of noise. At the same time, we likely introduced a small amount of change to the actual contents of the image.
Typically, in generating the training data for diffusion models, we add noise incrementally to an image until it’s essentially all noise. Going backwards from almost all noise to the original images directly in one step is a pretty dubious proposition.
hanrelan
I was wondering the same and this video [1] helped me better understand how the prediction is used. The original paper isn't super clear about this either.
The diffusion process predicts the total noise that was added to the image. But that prediction isn't great and applying it immediately wouldn't result in a good output. So instead, the noise is multiplied by a small epsilon and then subtracted from the noisy image. That process is iterated to get to the final result.
nullc
You can think of it like solving a differential equation numerically. The diffusion model encodes the relationships between values in sensible images (technically in the compressed representations of sensible images). You can try to jump directly to the solution but the result won't be very good compared to taking small steps.
cgearhart
I’m pretty sure it’s a stability issue. With small steps the noise is correlated between steps; if you tried it in one big jump then you would essentially just memorize the input data. The maximum noise would act as a “key” and the model would memorize the corresponding image as the “value”. But if we do it as a bunch of little steps then the nearby steps are correlated and in the training set you’ll find lots of groups of noise that are similar which allows the model to generalize instead of memorizing.
jayalammar
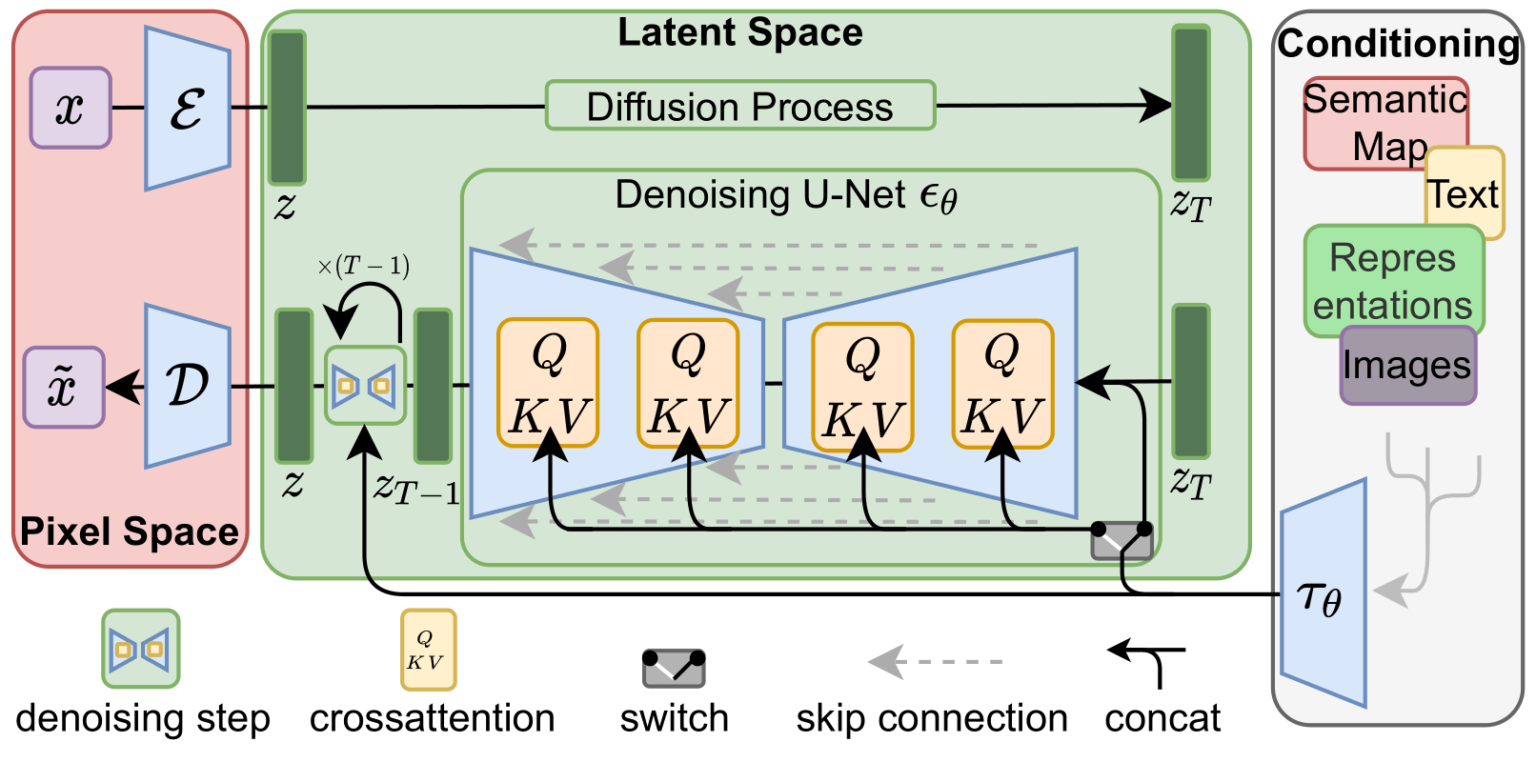
Two diffusion processes are involved:
1- Forward Diffusion (adding noise, and training the Unet to predict how much noise is added in each step)
2- Generating the image by denoising. This doesn't predict the final image, each step only predicts a small slice of noise (the removal of which leads to images similar to what the model encountered in step 1).
So it is indeed an iterative processes in that way, each step taking one step towards the final image.
minimaxir
Hugging Face's diffusers library and explainer Colab notebook (https://colab.research.google.com/github/huggingface/noteboo...) are good resources on how diffusion works in practice codewise.
jayalammar
Agreed. "Stable Diffusion with Diffusers" and "The Annotated Diffusion Model" were excellent and are linked in the article. The code in Diffusers was also a good reference.
BrainVirus
https://jalammar.github.io/images/stable-diffusion/article-F...
{kind=link}
Can you say with a straight face that this image (from the original paper) was intended to explain rather than obfuscate?
backpropaganda
Yes, I can read it perfectly fine. It relies on a lot of notation that AI researchers are familiar with.
undefined
MacsHeadroom
It's as clear as wiring diagram for me. But I read a lot of ML literature.
herval
If you're in AI research, that's a pretty standard diagram
torbTurret
Love the visual explainers for machine learning nowadays.
The author has more here: https://jalammar.github.io/
Amazon has some highly interactive ones here: https://mlu-explain.github.io/
Google had: distill.pub
Hope to see education in this space grow more.
culi
> Google had: distill.pub
Wait I thought they were just taking a break. Don't tell me it's being killed
swyx
i've been collecting other explanations of how SD works here: https://github.com/sw-yx/prompt-eng#sd-model-values
wwarek
Another very good (although less deep) explanation was published yesterday by Computerphile:
cl3misch
I also thought about this video while reading the HN post. The Computerphile video completely omits the latent space, right? But instead spends a lot of time on the iterative denoising. Even though I like Computerphile a lot, I don't think this was the best tradeoff.
renewiltord
Isn't it really cool? It's like the AI is asking itself what shapes the clouds are making and whether the moon has a face, over and over again.
mkaic
This is one of the best analogies I've heard for denoising diffusion models. I'm totally stealing this the next time my parents ask me how it works :P
vanjajaja1
This is the perfect level of description, thank you. Looking forward to checking out more of your work.
uptown
“We then compare the resulting embeddings using cosine similarity. When we begin the training process, the similarity will be low, even if the text describes the image correctly.”
How is this training performed? How is accuracy rated?
kuu
Cosine similarity is a fixed way of comparing two vectors, so we can think of it as making a difference: A-B = d
If d is close to 0, we say that both embeddings are similar.
If d is close to 1, we say that both embeddings are different.
Imagine we have the following data:
- Image A and its description A
- Image B and its description B
We would generate the following dataset:
- Image A & Description A. Expected label: 0
- Image B & Description B. Expected label: 0
- Image A & Description B. Expected label: 1
- Image B & Description A. Expected label: 1
The mixture of Image Y with Description Z with Y!=Z is what we call "negative sampling"
If the model predicts 1 but the expected value was 0 (or the other way around), it's a miss, and therefore the model is "penalized" and has to adjust the weights; if the prediction matches the expectation, it's a success, the model is not modified.
I hope this clears it
spywaregorilla
I'd be curious to see an example gallery of image generation of the same vector scaled to different magnitudes. That is, 100% cosine similarity, but still hitting different points of the embedding space.
The outcome vectors aren't normalized right? So there could be a hefty amount of difference in this space? Maybe not on concept, but perhaps on image quality?
kuu
> The outcome vectors aren't normalized right?
I'm not sure about it, maybe they are, it wouldn't be strange
> So there could be a hefty amount of difference in this space? Maybe not on concept, but perhaps on image quality?
Sure, each text could have more than one image matching the same representation (cosine wise), but maybe the changes wouldn't look much as "concepts" in the image but other features (sharpness, light, noise, actual pixel values, etc)
It would be curious to check, definitely
uptown
Thanks very much! That helped me understand the concept better.
mwambua
From the paper on the CLIP embedder it appears that they use a form of contrastive loss that maximizes the cosine similarity between related images and prompts, but also minimizes the same between unrelated prompts & images.
See section 2.3 of the CLIP paper: https://arxiv.org/pdf/2103.00020.pdf
Also, the writeup on OpenAI's blog: https://openai.com/blog/clip/
jmartrican
So its like the How to Draw an Owl meme.
thunderbird120
You can do that, yes https://0x0.st/oJVK.webm
minimaxir
SD has made this meme into a reality, given how easy it is to take a sketch and use img2img to get something workable out of it.
Get the top HN stories in your inbox every day.
Closer. But I still get lost when words like “tensor” are used. “structured lists of numbers” really doesn’t seem to explain it usefully.
This reminds me that explaining seemingly complex things in simple terms is one of the most valuable and rarest skills in engineering. Most people just can’t. And often because they no-longer remember what’s not general knowledge. You end up with a recursive Feynmannian “now explain what that means” situation.
This is probably why I admire a whole bunch of engineering YouTubers and other engineering “PR” people for their brilliance at making complex stuff seem very very simple.